



































帶你了解mapreduce

計算機編程是一門復(fù)雜的學(xué)問,但也不阻礙它仍有許多狂熱追求者。在編程中,會有很多編程模型。編程模型,可以簡單地理解為模板,遇到相似問題,程序員可以模板化解決,這樣就減輕了程序員的工作負(fù)擔(dān)。不同的編程環(huán)境和不同的應(yīng)用對象,會有對應(yīng)的不同的編程模型。今天我們來了解一下mapreduce這個編程模型,這是應(yīng)用于大規(guī)模數(shù)據(jù)集群的并行運算。Map是映射,Reduce是化簡。簡單來說,這個模板的特性,是讓不會分布式并行編程的人員,可以將程序運行在分布式系統(tǒng)上。
目錄
1. 如何簡單的理解mapreduce的應(yīng)用
2. mapreduce的主要技術(shù)特征
3. mapreduce的其他技術(shù)特征
4. mapreduce和Spark的區(qū)別是什么
5. 初學(xué)mapreduce的常見問題
-
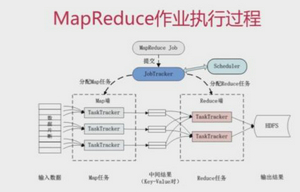
如何簡單的理解mapreduce的應(yīng)用
mapreduce的應(yīng)用理念其實很簡單,就是把一些數(shù)據(jù)先通過map(映射)進行歸類,再通過reducer把同一類的數(shù)據(jù)進行化簡處理。我們可以理解為,mapreduce是基于兩個哲學(xué)原理設(shè)計的,大而化小和異而化同。接收到很多復(fù)雜數(shù)據(jù),我們第一步就會先把數(shù)據(jù)分類,這就是異而化同。分類之后再進行細(xì)項分割,把數(shù)據(jù)切分成小塊后,就可以并發(fā)或者批量處理了,這就是大而化小。map的工作就是分類數(shù)據(jù),然后輸出,reducer接收到的都是同類數(shù)據(jù)再進行分割處理。
-
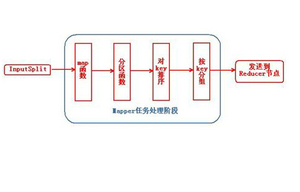
mapreduce的主要技術(shù)特征
在了解過mapreduce的功能后,我們來了解一下mapreduce設(shè)計技術(shù)都有什么主要特征。1、因為mapreduce需要進行大規(guī)模的數(shù)據(jù)處理,并由大量的數(shù)據(jù)出錯需求,所以在集群的構(gòu)建上,我們要選擇低端的商用服務(wù)器,由外橫向擴展。2、使用的是低端的商用服務(wù)器,所以節(jié)點硬件失效是很常見的,因此設(shè)計的時候要考慮到不影響服務(wù)質(zhì)量的高容錯計算系統(tǒng),并且在節(jié)點失效后能夠自動加入加群。3、mapreduce會采用就近原則,將無法計算的數(shù)據(jù)轉(zhuǎn)移傳輸?shù)骄徒梢杂嬎愕墓?jié)點,而不僅限于數(shù)據(jù)的處理。
-
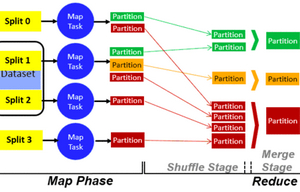
mapreduce的其他技術(shù)特征
除了剛才介紹的主要技術(shù)特征外,想要做好mapreduce設(shè)計,還要處理好以下三個方面。1、因為mapreduce需要大規(guī)模的處理數(shù)據(jù),所以在內(nèi)存中儲存處理所有數(shù)據(jù)的難度很大,借助硬盤順序訪問處理的技術(shù),可以大大提升處理速度。2、復(fù)雜度極高的編程其實對開發(fā)者的認(rèn)知和判斷造成了巨大的負(fù)擔(dān),而mapreduce要提供抽象機制,將程序員與系統(tǒng)層細(xì)節(jié)隔離開來,程序員僅需描述需要計算什么,具體如何計算可交由系統(tǒng)的執(zhí)行框架處理。3、為了提升計算速度和數(shù)據(jù)處理規(guī)模,mapreduce的節(jié)點設(shè)計需要有很強的可擴展性。
-
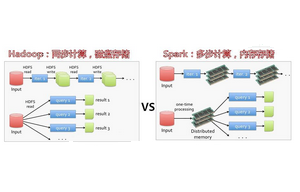
mapreduce和Spark的區(qū)別是什么
對于很多剛接觸編程的人來說,通常會無法完全理解mapreduce和spark的應(yīng)用區(qū)別。首先我們應(yīng)該明確,mapreduce是分布式運算的編程框架,而Spark可以兼容HDFS、Hive等,可以融入hadoop的系統(tǒng)。這兩者的區(qū)別,主要表現(xiàn)在:1.spark基于內(nèi)存的運算,要比mapreduce快100倍,基于硬盤的運算,要比mapreduce快10倍。2.spark支持流式、離線運算,而mapreduce則只支持離線運算。3.mapreduce必須運行在資源系統(tǒng)上,而spark本身集成資源調(diào)度,可以運行在自身的Master、worker或者yarn上。
-

初學(xué)mapreduce的常見問題
不管怎樣,想要真正學(xué)會、理解、應(yīng)用一種編程方式,都不是容易的事情。對于mapreduce初學(xué)者來說,經(jīng)常會問,mapreduce的輸入源可以是視圖嗎?答案是,這是不可以的,只能是表,這樣把結(jié)果寫入到表或分區(qū)時,才會覆蓋掉原有的數(shù)據(jù)。除此之外,初學(xué)者還應(yīng)該了解到Mapper中輸入的每條Record數(shù)據(jù),可以按序號讀取,也可以按照列名來獲取record,但是reduce.setup不能讀入輸入表,只能讀cache table。mapreduce在執(zhí)行時,不可以調(diào)用shell文件,會被沙箱阻擋。如果還想要了解更多關(guān)于mapreduce的常見問題,建議初學(xué)者可以多看一些文檔。
- 關(guān)于cms系統(tǒng)設(shè)計的小知識
- 中企動力提醒:網(wǎng)絡(luò)違法案例,等保刻不容緩
- 中企動力:網(wǎng)站運營怎么做之統(tǒng)計后臺篇
- 中企動力:網(wǎng)站運營難不難?
- 中企動力在5G時代給企業(yè)的小建議
- 中企動力:個人建站需要哪些能力?
- 中企動力:公司網(wǎng)站被黑怎么辦?
- 中小企業(yè)數(shù)字經(jīng)濟論壇召開,中企動力助力企業(yè)數(shù)字化轉(zhuǎn)型
- 中企動力:教你如何建立“新型”企業(yè)網(wǎng)站
- 肉驢養(yǎng)殖利潤效益分析
- 在線建網(wǎng)站靠譜嗎?在線建網(wǎng)站常問的5個問題!
- 營銷廣告人員必看,市場分析包括哪些方面?
- 揭秘:在線建網(wǎng)站內(nèi)幕曝光,80%老板都被騙了
- 優(yōu)秀的廣告設(shè)計理念需要具備的基本要素
- 廣告聯(lián)盟的特點
- 數(shù)據(jù)庫在建立信息管理系統(tǒng)中的特點
- 抖音和今日頭條的關(guān)系淺析
- 你真的會寫品牌推廣計劃嗎?
- 你了解linux運維工程師嗎
- 微信推廣平臺如何起到良好的宣傳作用





